
연관분석: 대용량 데이터베이스에서 빈도가 높은 아이템 간 연관규칙을 발견하는 기법
머신러닝의 비지도학습
평가지표: 지지도, 신뢰도, 리프트
지지도

신뢰도
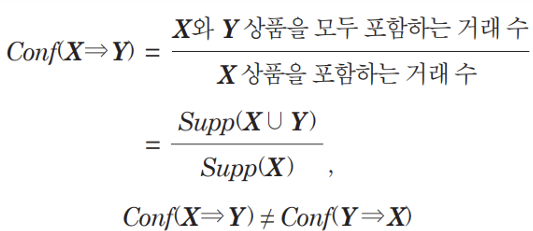
리프트

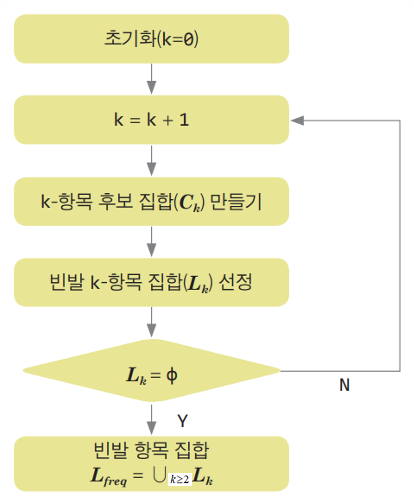
연관분석 절차
* 최종적으로 2항목 이상의 빈발 항목 집합에 대한신뢰도와 리프트를 구하여 연관규칙을 발견한다.
지지도 40% 이상만 필터링 - Confidence 70% 이상만 필터링 - Lift 100% 이상만 필터링.
(이때 값은 탐색적 데이터 분석 후 결정)
실습

1단계: 패키지 임포트
from mlxtend.frequent_patterns import apriori, association_rules
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
import matplotlib.pyplot as plt
2단계: 데이터 작성
# 장바구니 데이터
tran = [['A','B','C','D','E'], ['B','C'], ['A','B','F'], ['A','B','G'],['A','F','H']]
#데이터세트를연관분석이가능한배열로변환
te=TransactionEncoder()
tran_ar=te.fit(tran).transform(tran)
print(tran_ar)
#열이름
print(te.columns_)
# 출력
[[ True True True True True False False False]
[False True True False False False False False]
[ True True False False False True False False]
[ True True False False False False True False]
[ True False False False False True False True]]
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
df = pd.DataFrame(tran_ar, columns = te.columns_)
print(df)# 출력
A B C D E F G H
0 True True True True True False False False
1 False True True False False False False False
2 True True False False False True False False
3 True True False False False False True False
4 True False False False False True False True# 각 상품별 거래 빈도
freq=df.sum().to_frame('Frequency')
# 빈도 역순으로 정렬
freq_sort = freq.sort_values('Frequency',ascending=False)
print(freq_sort) Frequency
A 4
B 4
C 2
F 2
D 1
E 1
G 1
H 1
#지지도
freq_sort['Support'] =freq_sort['Frequency']/len(tran)
print(freq_sort) Frequency Support
A 4 0.8
B 4 0.8
C 2 0.4
F 2 0.4
D 1 0.2
E 1 0.2
G 1 0.2
H 1 0.2
# 빈발항목과 지지도
freq_items = apriori(df, min_support=0.4, use_colnames=True)
print(freq_items) support itemsets
0 0.8 (A)
1 0.8 (B)
2 0.4 (C)
3 0.4 (F)
4 0.6 (A, B)
5 0.4 (A, F)
6 0.4 (B, C)
# confidence 0.7 이상만 필터링
rules = association_rules(freq_items, metric="confidence",min_threshold=0.7)
rules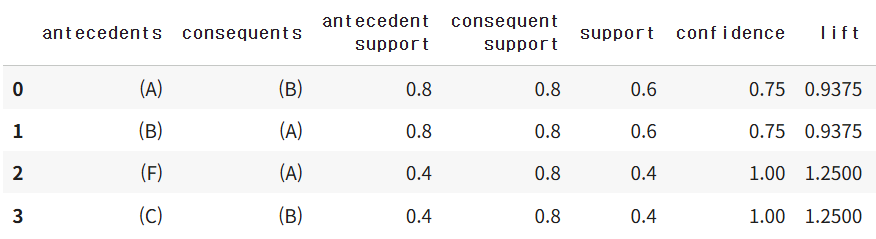
# lift 1이상만 필터링
rules = rules[(rules['lift']>1)]
rules.sort_values(by='confidence',ascending=False)
'AI Study > Machine Learning' 카테고리의 다른 글
| 의사결정나무: Decision Tree (0) | 2025.12.15 |
|---|---|
| SVM: Support Vector Machine (0) | 2025.12.15 |
| K-최근접 이웃: KNN, K-nearest neighbors (0) | 2025.12.15 |
| 군집화, K-Means Clustering (1) | 2025.10.28 |
| 주성분 분석, PCA: Principal Component Analysis (0) | 2025.10.28 |